
Software is the Platform - Programming Lies
Ignoring hardware realities makes you a digital vampire


I feel the cursor move sluggishly as I type into VSCode on my high-end desktop computer. It drives me nuts. Not so much because of the delay, but because I know that software doesn't have to be like this.
Microsoft can't even conceive that their applications should open instantly, putting the smallest option in a survey about expected load time as "less than 10 seconds"1.
Applications that have an entire web browser under the hood plague our systems, eating up our RAM. This is a screenshot from my laptop as I type this.
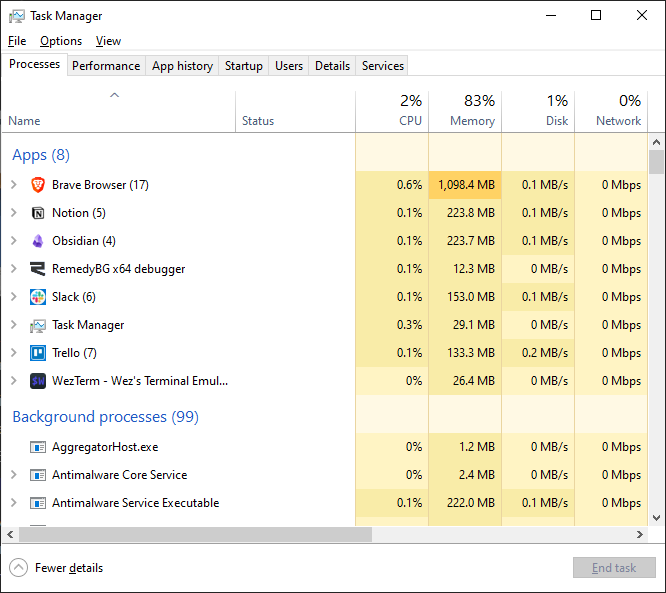
Windows uses an ungodly amount of memory these days, and these web applications on top are doing me no favours.
My laptop is intentionally low-end (Lenovo T480s). I write software to run fast on this thing and know it'll run fast on most devices.
For reference, the global average computer has 12 GB ram, and this has 8 GB.
Most people struggle with less than 16 GB these days, it's absurd.
I haven't even talked about games, as it's not the focus of this article, but the issue is huge in the game development space too. AAA developers tell their customers to "just buy better hardware".
Being willfully ignorant about the hardware isn't cool. It's unprofessional.
Disregarding the user's time is vampiric. You are trading your time for theirs, in a real sense.
By the end of this article, you'll have three key concepts to keep in mind that'll help you avoid being a digital vampire:
Plain old data
Data locality
Access patterns
Plain Old Data
Code is code. Data is data. Objects aren't real. It's all a psyop.
Treating instances of datum as if they are singular pieces with agency is something all too common. A Message class that has a send(User to) method is one such example.
Take these two ways to write that functionality:
message.send(recipient)
// vs
message_send(message_data, recipient)The difference may seem trivial, but one frames your thinking in a deceptive way.
When you call message.send, the message isn't "sending itself". A function is being called, and a pointer to the message is being passed as the first argument implicitly.
The second example more accurately reflects the reality of programs: all programs are about transforming data.
When you consider programs as fractal data transformation tools, you come to sane conclusions about how to structure them.
For example, if we wanted to send 100 different messages to 100 recipients... Let's do it a way that would be common with the first version:
messages = [100]MessageData{...}
recipients = [100]Recipient
for message, i in messages {
message.send(recipients, recipients[i])
}Do you see what's wrong with this? Maybe the compiler will be smart enough to catch it in this contrived example, but compilers are not magic. They are notoriously capricious when it comes to good code generation.
The issue is that we are dispatching a function call for every message, setting up the stack for calling into the function, then sending a message, then tearing it down, repeat 100 times.
What about the other method?
messages = [100]MessageData{...}
recipients = [100]Recipient
send_messages_batch(messages, recipients)Here we are passing entire arrays of data to be processed at once.
This function wasn't outlined in the contrived example description - but, here's the thing: It can't exist with the mind-state of the first style.
If a message is a singular object, then how can it have a method that sends it and 99 others to 100 recipients? It seems absurd due to the thought patterns of thinking about individuals vs collections.
Treating data as data and programs as data transformers unlocks performance by default, especially when taking the next two points into account.
Data Locality
Keeping data close together in memory allows the CPU to use it efficiently.
This is because all modern CPUs have caches. The CPU pulls in data it thinks your program is about to use and stores it in the cache. Then, when correct, it grabs it from the cache instead of RAM.
These are L1, L2, and sometimes L3. Each cache increases in size and thus increases in real-world distance from where the work is done.
The time required to get the data is much higher in the L3 cache, and significantly higher in RAM, than in L1.

Rough averages. Time based on 3.5-5 GHz CPU
There is a lot more to this picture. The thing to keep in mind is to try and fit the data for your transformation in the L1 or L2 where possible, and try to go out to RAM rarely.
Another thing to note, is the L1 and L2 are per core caches. That means you can multiply the cache size you have access to by learning how to use threads effectively.
Access Patterns
Finally, there are access patterns. This goes hand in hand with data locality.
The CPU will try to predict what data your program needs and prefetch it into the caches. If you choose an algorithm that jumps around a lot in memory, the CPU may prefetch the wrong data. This is called a cache miss, and it's a performance killer.
Since going to memory is so slow, if every iteration of an algorithm is causing a cache miss, the algorithm may take 100x longer than it could have.
Let's look at a classic example, and how to fix it without changing data structures. The Linked List.
LinkedListNode {
LinkedListNode *next
int data
}
head = new LinkedListNode
head.data = 32
node1 = new LinkedListNode
node1.data = 42
linked_list_append(head, node1)
// some time later in the program
node2 = new LinkedListNode
node2.data = 42
linked_list_append(head, node2)
// etc, repeat however many timesWe have this linked list with individually allocated nodes.
Each node has no guarantee about its location in memory due to using the default allocator (new).
This could be disastrous for performance as the memory may be scattered around and each time you walk the list, you may have cache misses on every next lookup.
The mistake people make in the Linked List vs Arrays argument is assuming this is the only way to make a linked list.
Let's look at another way to make a linked list, but keep the memory close together.
LinkedListNode {
LinkedListNode *next
int data
}
MAX_REQUIRED_NODES = 100
nodes = new [MAX_REQUIRED_NODES]LinkedListNode
nextNode = 0
alloc_node() -> LinkedListNode * {
node = &nodes[nextNode]
nextNode += 1
return node
}
head = alloc_node()
head.data = 32
node1 = alloc_node()
node1.data = 42
linked_list_append(head, node1)
// some time later in the program
node2 = alloc_node()
node2.data = 42
linked_list_append(head, node2)
// etc, repeat however many timesA few extra lines, some thinking about limits, and we have a linked list that will perform nearly as well as an array.
There are a bunch of different ways you could achieve something similar, here are two methods to use without having to define a maximum:
Use indices instead of next pointers, and a backing array
Use a growable arena allocator
By thinking about how data is stored and accessed, you unlock hundreds of times faster programs without much, or in some cases zero extra code.
Conclusion
Software runs on hardware. Hardware is the platform. Hardware has physical constraints and considerations. Abstracting away the hardware is not possible.
When writing code that needs to run fast, consider these simple questions:
Am I treating data as data, or pretending objects have agency?
Is related data stored close together in memory?
Are my access patterns using close-together data?
These questions force you to think about the reality of computers. You'll write code that performs better without huge refactoring efforts.
Understanding these basics isn't just for systems programmers or game developers. Every professional programmer has a responsibility to have at least a shallow understanding of these concepts.
Don't be the programmer who drains users' lifeblood one sluggish interaction at a time, when you could easily write code that respects it.
Handmade Hero | Visual Studio Survey
If you enjoy this newsletter and want to go deeper, with more structure, I made Program Video Games for you. Transform your game ideas into working systems from first principles.
Reading you posts with great interest. Don’t know when I subscribed and why - but keep going mate
> “Trading your time for theirs”
100%.
A personal puzzle: I’m always frustrated by the long load times on Notion. I’m just like… stop rearranging the buttons on the page and just make it 2 seconds faster! At the same time, when I’m prioritizing new features with customers, I always bring up performance improvements and they ALWAYS say “eh we can live with that, we’d rather have [some other thing] now”. Am I just seeing short-termism? Maybe Notion is just at a very different stage in their relationship to users. Idk